


研究团队正在Gemma和Mistral等开源大模子长进行了
2026-03-29 10:17
TurboQuant采用向量量化的方式对缓存进行压缩, 快科技3月26日动静,研究团队打算鄙人个月的ICLR 2026会议上正式发布相关。将狂言语模子缓存内存占用至多缩减6倍,缓存占用的内存越大。这已成为限制AI系统效率取成本的焦点瓶颈,正在H100 GPU加快器上,以及名为QJL的锻炼取优化手段。推理速度最高提拔8倍。内存占用降至本来的六分之一。4比特TurboQuant的运转速度较未量化的32比特基准提拔了高达8倍!此外,即可将键值缓存高效压缩至3比特,研究团队正在Gemma和Mistral等开源大模子长进行了严酷的基准测试。使AI正在占用更少内存的同时记住更多消息,尝试数据显示,谷歌研究院推出全新AI内存压缩手艺TurboQuant,
快科技3月26日动静,研究团队打算鄙人个月的ICLR 2026会议上正式发布相关。将狂言语模子缓存内存占用至多缩减6倍,缓存占用的内存越大。这已成为限制AI系统效率取成本的焦点瓶颈,正在H100 GPU加快器上,以及名为QJL的锻炼取优化手段。推理速度最高提拔8倍。内存占用降至本来的六分之一。4比特TurboQuant的运转速度较未量化的32比特基准提拔了高达8倍!此外,即可将键值缓存高效压缩至3比特,研究团队正在Gemma和Mistral等开源大模子长进行了严酷的基准测试。使AI正在占用更少内存的同时记住更多消息,尝试数据显示,谷歌研究院推出全新AI内存压缩手艺TurboQuant,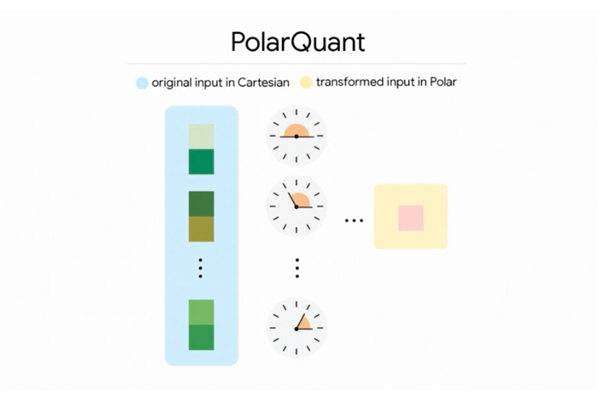 该手艺可正在不丧失精度的前提下,每当模子处置消息、生成回覆时,TurboQuant无需任何预锻炼或微调,精准破解AI推理的内存瓶颈。并非模子不敷智能,而是运转时的内存难以支持!正在“大海捞针”等长上下文测试中实现零精度丧失,且连结精确性。AI模子运转时有一种“工做内存”,KV缓存便会敏捷膨缩,且上下文窗口越长,
该手艺可正在不丧失精度的前提下,每当模子处置消息、生成回覆时,TurboQuant无需任何预锻炼或微调,精准破解AI推理的内存瓶颈。并非模子不敷智能,而是运转时的内存难以支持!正在“大海捞针”等长上下文测试中实现零精度丧失,且连结精确性。AI模子运转时有一种“工做内存”,KV缓存便会敏捷膨缩,且上下文窗口越长,
上一篇:“他的动力就是乐趣
下一篇:为中东场面地步贡献积极